
.avif)
Website content extraction has become a crucial skill for researchers, marketers, and data analysts. As YouTube continues to dominate the online video industry, the ability to scrape and analyze its vast repository of content is more valuable than ever. This guide delves into the intricacies of extracting data from YouTube, offering insights into the tools and techniques that will shape the field in 2025.
This guide will explore various methods to scrape YouTube data, including extracting information from channels, playlists, and videos.
We’ll explore the fundamentals of web scraping and set up a robust environment for your projects. The guide will cover advanced YouTube scraping techniques, ensuring you can handle the platform’s complexities. We’ll also discuss best practices to keep your scraping operations efficient and scalable. By the end, you’ll have a comprehensive understanding of effectively extracting and leveraging YouTube content, staying ahead in today’s world.
Introduction to YouTube Data Extraction
In the digital age, YouTube data extraction has emerged as a powerful tool for businesses, researchers, and marketers. This process involves collecting and extracting data from YouTube videos, channels, and search results to gain valuable insights. Whether you’re conducting market research, performing sentiment analysis, or gathering business intelligence, YouTube data can provide a wealth of information about your target audience.
By extracting data from YouTube, you can analyze viewer behavior, track engagement metrics, and identify trending content. This information is crucial for making informed decisions and staying ahead in a competitive landscape. With the rise of big data and analytics, the ability to scrape YouTube videos and extract meaningful data has become an essential skill for anyone looking to leverage online content for strategic purposes.
Understanding Web Scraping Fundamentals
What is web scraping?
Web scraping is a technique to gather data from websites automatically. It involves using software or scripts to extract information from web pages, which can then be analyzed or utilized for various purposes. This process typically includes writing scripts or using specialized tools to collect specific data from web pages.
For instance, retail competitors often use web scraping to monitor product prices on e-commerce sites. By gathering pricing data, they can adjust their own prices to stay competitive. Researchers also employ web scraping to study patterns in scientific articles or scrape YouTube search results to gather data on trending videos.
Web scraping finds applications in both professional and personal contexts. It’s used to collect customer feedback about products or services, extract competitor data in a usable format, and gather information for machine learning projects. The stock market, social media trends, and search engine optimization are other areas where website content extraction proves valuable.
Legal and ethical considerations
When engaging in website content extraction, it’s crucial to navigate the legal and ethical landscape carefully. The legality of web scraping can vary depending on the methods used and whether it violates a website’s terms of service.
When performing a YouTube scrape, it is crucial to adhere to copyright and personal data regulations to avoid legal issues.
Several legal principles come into play:
- Terms of Service (ToS): Every website has a ToS agreement that users must follow. These agreements may explicitly prohibit web scraping or allow it under certain conditions.
- Copyright Law: Website content is often protected by copyright. Scraping and republishing entire articles without permission could violate copyrights.
- Computer Fraud and Abuse Act (CFAA): In the United States, this law prohibits unauthorized access to computer systems. Scraping websites in ways that violate their terms of service or overload servers may breach this law.
- Privacy Laws: Scraping personal data from websites could involve privacy laws like the GDPR in the EU or the CCPA in the US. Unauthorized gathering of personal information can lead to legal responsibilities.
Ethical considerations are equally important. Respecting website owners’ rights, protecting individuals’ privacy and security, and maintaining transparency about scraping activities are crucial. It’s essential to scrape only the necessary data, respect the Robots Exclusion Standard (robots.txt), and avoid deceptive practices.
Common challenges in web scraping
Website content extraction comes with several challenges that can make the process tricky. Some of the most notable obstacles include:
- Bot Detection: Websites often employ sophisticated systems to spot automated scraping activities. These systems analyze user agent strings and request rates to differentiate between human users and bots.
- CAPTCHAs: These challenges are designed to weed out bots by presenting tasks that are easy for humans but difficult for machines to solve.
- Dynamic Content: Many modern websites use client-side rendering technologies like JavaScript to generate dynamic content, making traditional HTML-based scraping techniques less effective.
- Rate Limiting: Websites may limit the number of requests a client can make in a given period to prevent server overload.
- Page Structure Changes: Websites periodically update their user interfaces, requiring scrapers to be updated to target the correct elements.
- Anti-Scraping Technologies: Some websites use advanced techniques to thwart scraping attempts, such as IP blocking mechanisms.
- Data Quality: Ensuring that the scraped data meets quality guidelines in real-time can be challenging.
Collecting video links and their corresponding titles is essential for various business purposes, but it can be challenging due to dynamic content and anti-scraping measures.
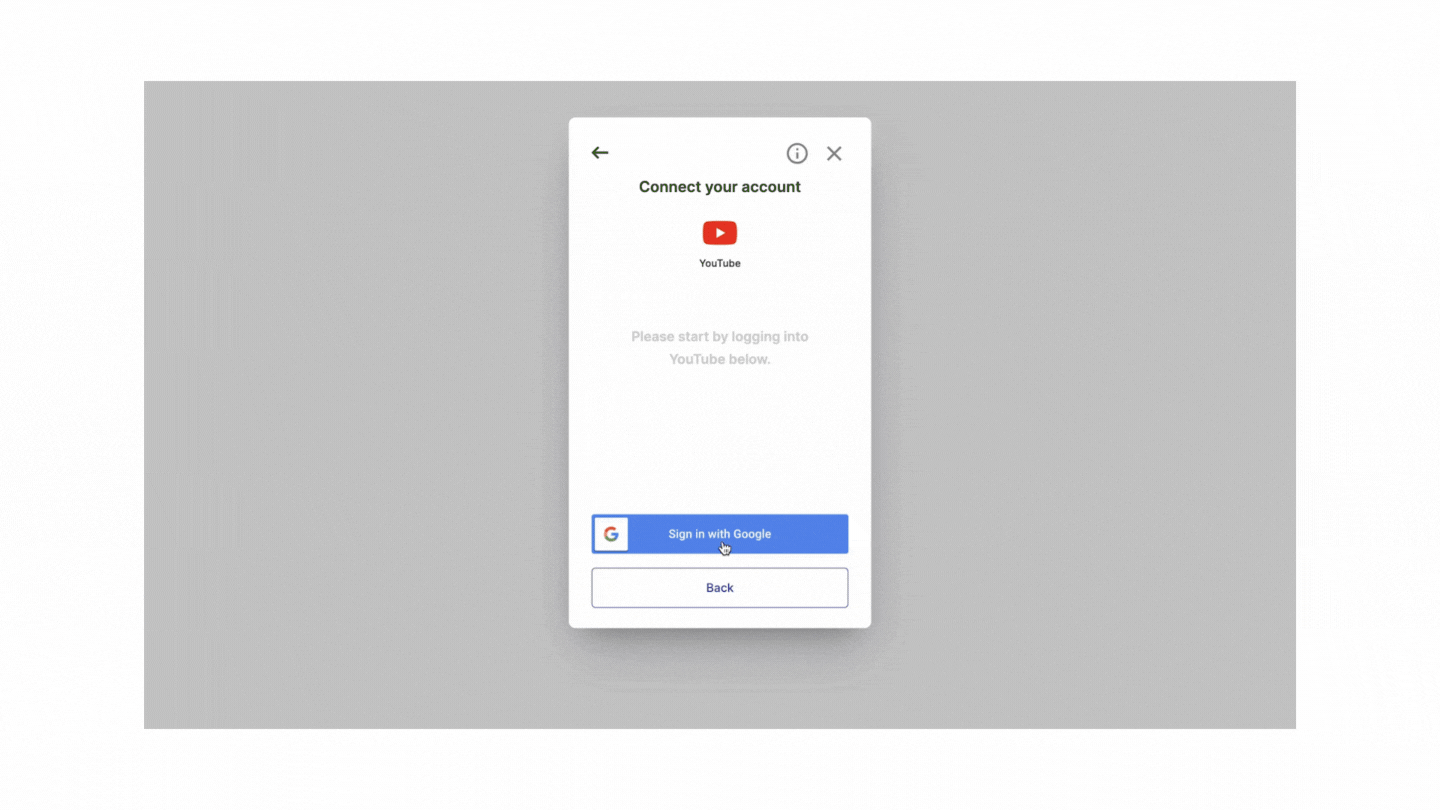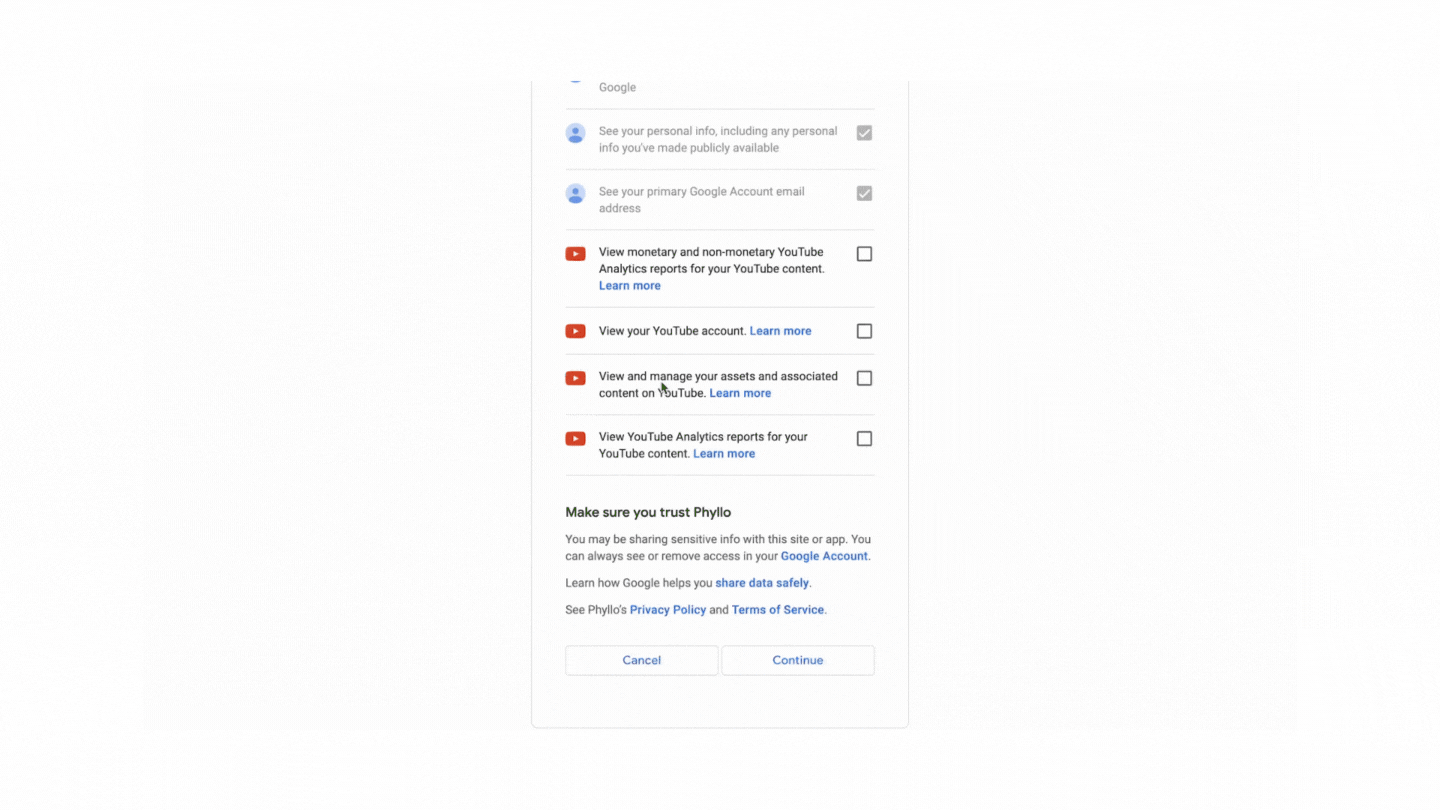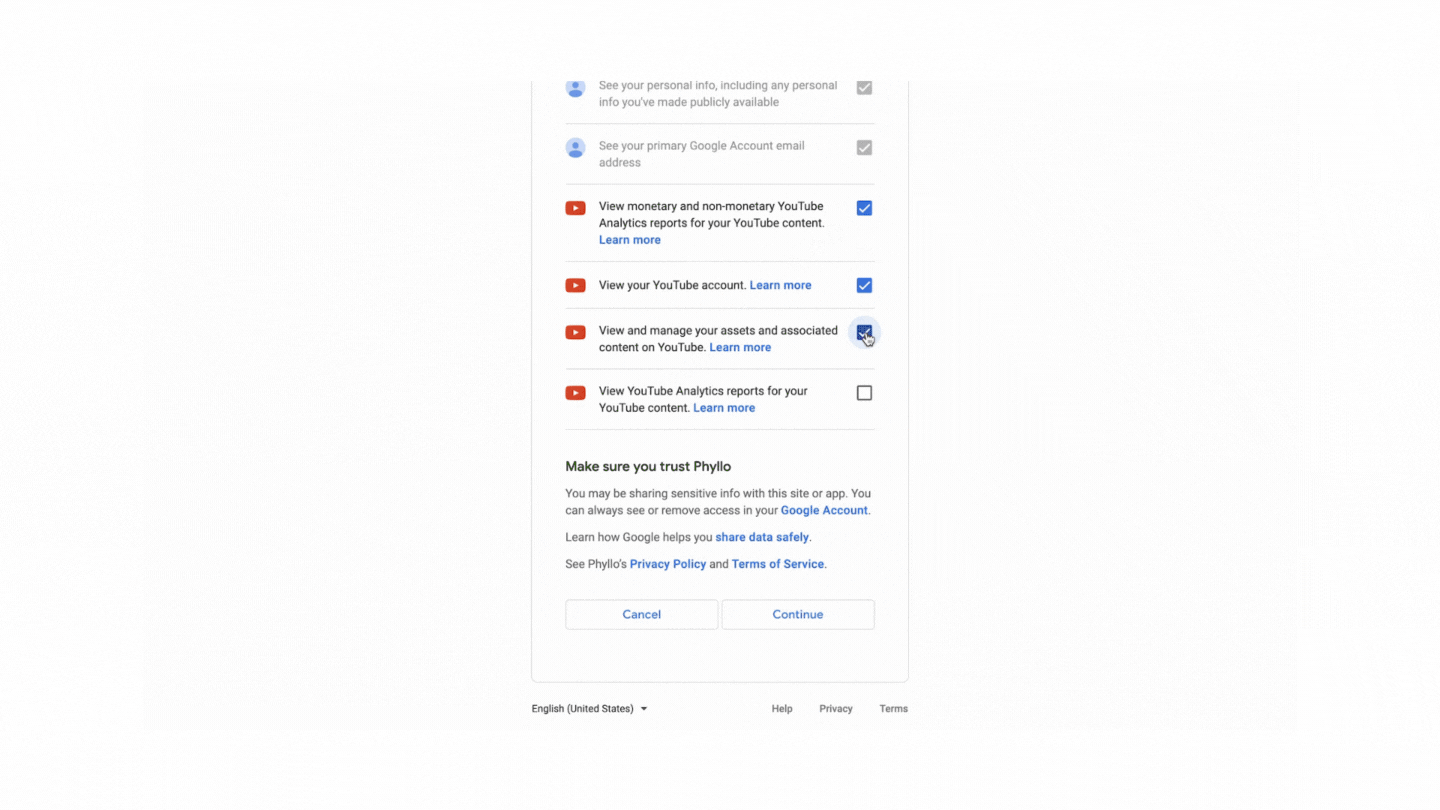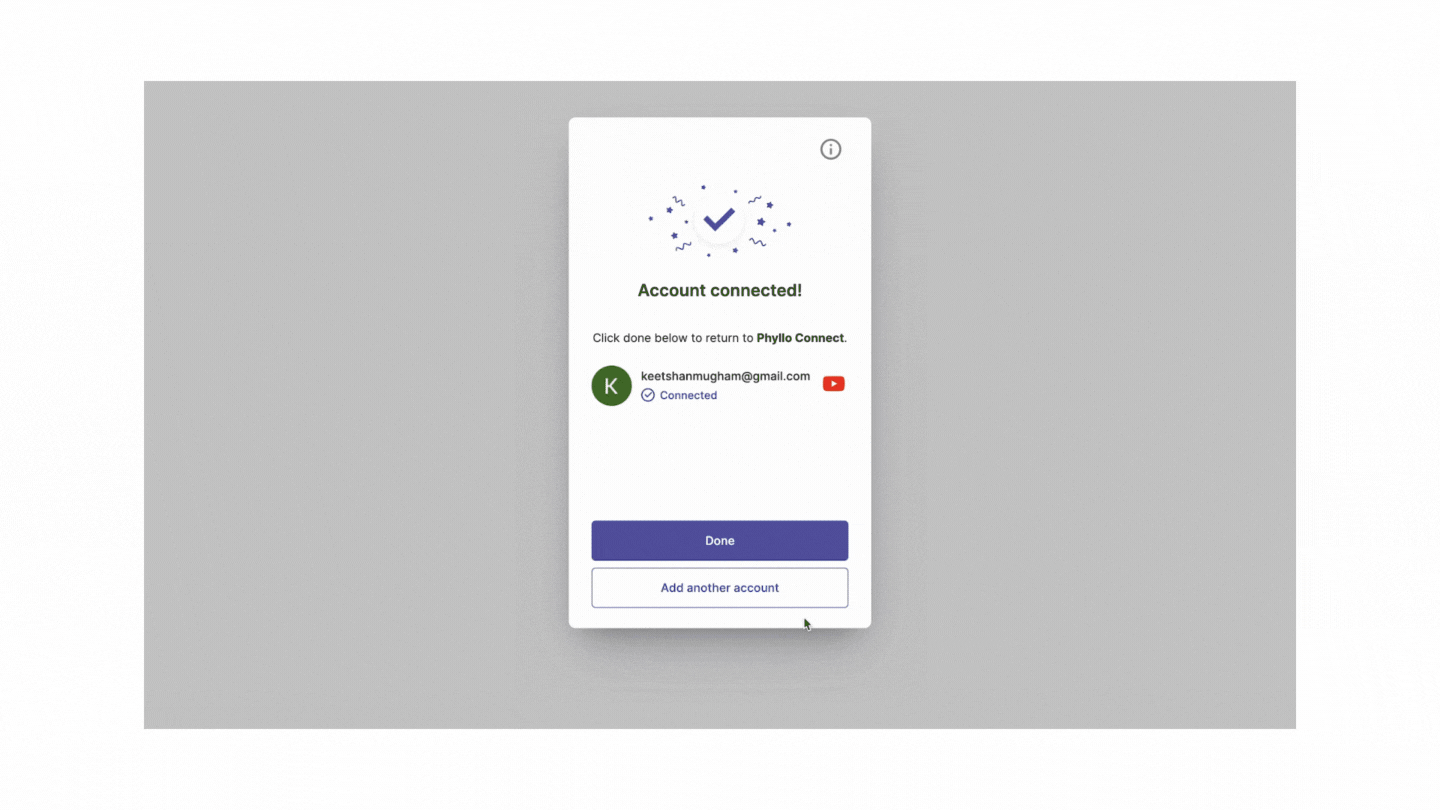
Overcoming these challenges often requires a combination of technical strategies, ethical considerations, and adherence to legal guidelines and web scraping best practices.
Setting Up Your Web Scraping Environment
Choosing the right programming language
When it comes to website content extraction, Python stands out as the top choice for many developers. Its simplicity, versatility, and abundance of libraries specifically designed for web scraping make it an ideal language for both beginners and advanced users. Python’s readability and extensive community support contribute to its popularity in the field.
Python’s capabilities make it an excellent choice for extracting YouTube video data, including titles, descriptions, and view counts.
For YouTube scraping, Python’s capabilities shine even brighter. The platform’s dynamic nature, which relies heavily on JavaScript for loading and rendering data, requires tools that can handle such complexity. Python, combined with libraries like Selenium, provides the perfect solution for scraping dynamic websites like YouTube.
Essential libraries and tools
To get started with web scraping in Python, you’ll need to install some key libraries. Here are the most important ones:
These libraries and tools are essential for extracting video data such as titles, descriptions, and performance metrics from YouTube.
- Requests: This HTTP library allows you to send HTTP requests easily, making it essential for extracting web content.
- Beautiful Soup: A powerful library for parsing HTML and XML documents, Beautiful Soup makes it simple to navigate and search through website code to find the needed data.
- Selenium: This tool is crucial for scraping dynamic websites like YouTube. It automates web browsers, allowing you to simulate user behavior and extract data from JavaScript-rendered pages.
- Scrapy: A comprehensive web scraping framework that’s particularly useful for large-scale projects.
- Playwright: This tool provides cross-browser automation and is excellent for handling modern web applications.
Configuring your development setup
To set up your web scraping environment, follow these steps:
- Install Python: Download and install the latest version of Python from the official website.
- Set up a virtual environment: This helps keep your project dependencies organized and avoids conflicts with other Python projects.
- Install required libraries: Use pip, the Python package manager, to install the necessary libraries. For example:
- pip install requests beautifulsoup4 selenium scrapy playwright
- Install a web driver: If you’re using Selenium, you’ll need to install a web driver corresponding to your preferred browser (e.g., ChromeDriver for Google Chrome).
- Configure your IDE: Choose a text editor or IDE that supports Python development. Popular options include Visual Studio Code, PyCharm, and Sublime Text.
For instance, you can use BeautifulSoup to extract the video title from the HTML of a YouTube page.
By following these steps, you’ll have a robust environment set up for website content extraction, including YouTube scraping. Remember to always respect websites’ terms of service and legal considerations when performing web scraping activities.
Advanced Web Scraping Techniques for YouTube Video Data
Handling dynamic content
YouTube’s dynamic content poses a challenge for traditional scraping methods. To overcome this, we need to use tools that can render JavaScript and interact with the page. One effective approach is to use requests-HTML, a Python package designed for scraping dynamic content.
Using tools like requests-HTML and Selenium, you can effectively scrape YouTube data from dynamically loaded pages.
To get started, install the requests-HTML package. This tool allows us to render JavaScript on the page, making it possible to access content that’s loaded dynamically. When using requests-HTML, you’ll need to create a session object and use its render method to execute JavaScript on the page.
Another powerful tool for handling dynamic content is Selenium. It automates web browsers, allowing you to simulate user behavior and extract data from JavaScript-rendered pages. Selenium is particularly useful for YouTube scraping as it can scroll through comments, click on buttons, and interact with the page just like a human user would.
Bypassing anti-scraping measures to scrape YouTube search results
YouTube, like many websites, employs anti-scraping techniques to protect its content. To bypass these measures, you’ll need to implement several strategies.
Bypassing anti-scraping measures allows you to extract valuable data from YouTube search results, such as video titles and links.
One effective method is IP rotation. By using a pool of IP addresses and rotating them for each request, you can avoid being blocked due to excessive requests from a single IP. Residential proxies are particularly useful for this purpose, as they appear more like genuine user traffic.
Another important technique is to mimic human behavior. This includes adding random delays between requests, using realistic user agents, and setting referrer headers. These steps make your scraper appear more like a regular user browsing the site.
CAPTCHAs can be a significant obstacle in website content extraction. While there’s no foolproof method to bypass them, you can use CAPTCHA-solving services or implement machine learning models to handle them automatically.
Extracting video metadata and scrape YouTube comments
To extract video metadata from YouTube, you can use the YouTube Data API. This official method allows you to retrieve information such as video titles, descriptions, view counts, and other valuable data. While it has usage limits, it’s a reliable and ethical way to extract metadata.
For scraping comments, you have several options. The YouTube Data API can be used to fetch comments, but it has limitations on the number of comments you can retrieve. For more comprehensive comment extraction, you might need to use custom scraping solutions to scrape YouTube comments effectively.
One effective method is to use a headless browser like Playwright or Puppeteer. These tools can scroll through the comments section, simulating user interaction to load all comments. You can then use BeautifulSoup or similar parsing libraries to extract the comment data from the loaded HTML.
When scraping comments, focus on extracting key information such as the comment text, author name, timestamp, and like count. You can also gather data on reply counts and nested replies if needed.
Remember to respect YouTube’s terms of service and implement rate limiting in your scraper to avoid overloading their servers. By combining these advanced techniques, you can create a robust YouTube scraper capable of handling dynamic content, bypassing anti-scraping measures, and extracting valuable metadata and comments for your website content extraction needs.
Extracting YouTube Channel Information
Understanding the performance and engagement of a YouTube channel is key to identifying successful content strategies and influential creators. Extracting YouTube channel information allows you to gather data such as the channel name, description, subscriber count, view count, and video titles. This data provides a comprehensive view of a channel’s reach and popularity.
By analyzing this information, businesses and researchers can identify trends and patterns that indicate what type of content resonates with audiences. For instance, you can track the growth of subscriber counts over time or compare view counts across different videos to determine which topics are most engaging. Additionally, extracting channel information can help you identify key influencers and popular content creators within your niche, enabling you to form strategic partnerships and collaborations.
Best Practices for Scalable and Efficient Scraping
Implementing rate limiting and delays
To ensure successful website content extraction, especially when dealing with YouTube, it’s crucial to implement rate limiting and delays. This practice helps avoid overloading servers and getting blocked. Implementing rate limiting and delays is essential when you scrape YouTube data to avoid overloading servers and getting blocked. By adding random delays between requests, you can mimic human behavior and reduce the chances of triggering anti-scraping measures.
One effective approach is to use a smart rotating proxy system. This automatically uses a random residential proxy server for each request, making it harder for websites to detect and block your scraping activities. However, it’s important to note that you don’t need to change the proxy server with every request if there’s an authentication session in place.
Parallel processing and multithreading
To speed up your YouTube scraping operations, consider implementing parallel processing and multithreading techniques. These methods allow you to handle multiple pages simultaneously, significantly reducing overall execution time.
Parallel processing and multithreading can significantly speed up the extraction of YouTube video data, such as titles and view counts.
Multithreading enables concurrent execution of tasks within a single program. By creating a thread pool and assigning scraping tasks to different threads, you can efficiently manage and reuse threads, avoiding the overhead of creating new ones for each task.
For CPU-bound operations, multiprocessing is often preferred over multithreading. It allows you to utilize multiple CPU cores, enabling true parallel execution of scraping tasks. This approach is particularly useful when dealing with a large number of URLs or complex data extraction processes.
Data storage and management strategies
Efficient data storage and management are crucial for large-scale YouTube scraping projects. As you extract vast amounts of data, you’ll need a robust strategy to handle and organize the information effectively. Efficient data storage and management are crucial for handling large volumes of video data extracted from YouTube.
One approach is to divide your data into two categories: raw and processed. Raw data, such as HTML documents crawled by your spiders, can be stored in cloud storage services. This allows for virtually unlimited storage space, though it comes with associated costs.
For processed data, which is typically the extracted information converted into new formats, consider using databases. Both relational and NoSQL databases can be suitable, depending on your specific needs. This approach allows for easier data retrieval and analysis.
When dealing with large datasets, it’s also important to implement efficient data cleaning processes. This includes removing duplicates, irrelevant items, and standardizing the format of extracted information. For YouTube comments, you might need to remove spam, punctuation, and emojis to prepare the data for analysis.
By following these best practices, you can create a scalable and efficient system for website content extraction from YouTube, ensuring smooth operations even when dealing with large volumes of data.
Using Extracted YouTube Data for Business and Research
The applications of extracted YouTube data are vast and varied, making it a valuable asset for both business and research purposes. For businesses, this data can be used to conduct competitive analysis, identify market trends, and understand consumer preferences. By analyzing competitors’ YouTube channels and videos, you can gain insights into their content strategies and audience engagement, allowing you to refine your own approach.
Researchers can leverage YouTube data to study human behavior, analyze social media trends, and explore the impact of online content on society. For example, sentiment analysis of YouTube comments can reveal public opinion on various topics, while view count trends can indicate the popularity of different types of content over time. Additionally, marketers can use this data to optimize their video content, improve their marketing strategies, and increase engagement on social media platforms.
YouTube Data Extraction Tools and Resources
To effectively extract data from YouTube, you’ll need the right tools and resources. Several web scraping tools, APIs, and software programs are available to help you gather and analyze YouTube data. Some popular tools for YouTube data extraction include:
- YouTube Scraper: A specialized tool designed for scraping YouTube videos, channels, and comments. It allows you to extract detailed information and perform comprehensive analysis.
- Scrapy: An open-source web scraping framework that can be used to build custom scrapers for YouTube. It’s particularly useful for large-scale projects.
- Selenium: A powerful tool for automating web browsers, making it ideal for scraping dynamic content on YouTube. Selenium can simulate user interactions and extract data from JavaScript-rendered pages.
In addition to these tools, there are numerous online resources and tutorials available to guide you through the process of YouTube data extraction. Websites like GitHub host repositories with sample code and projects, while forums and communities provide support and advice from experienced scrapers. By leveraging these tools and resources, you can efficiently extract and analyze YouTube data, gaining valuable insights to inform your business and research decisions.
Phyllo YouTube API Integration: Access Creator-Consented Data with Ease
With Phyllo's YouTube API integration, you can seamlessly access up-to-date, creator-consented YouTube data through just four APIs. This integration allows you to retrieve essential creator information, including profile details, content metrics, audience demographics, and income insights such as ad payouts and subscription revenue.
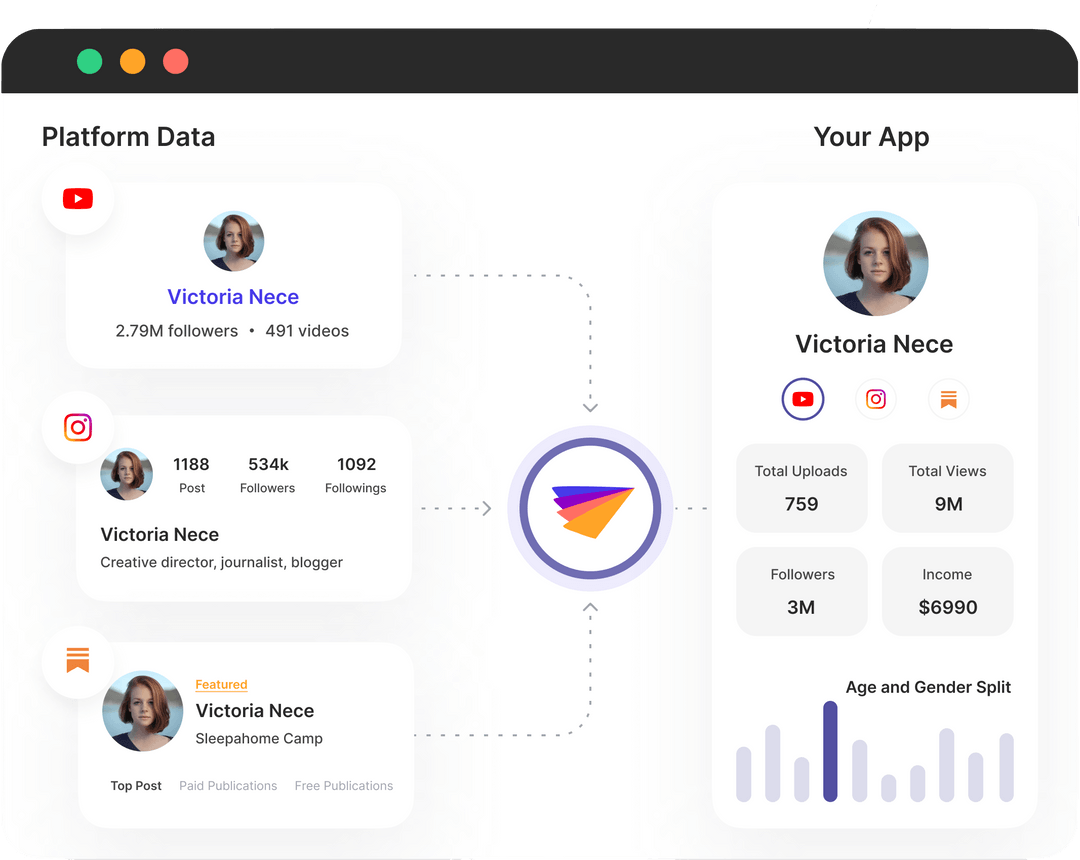
Phyllo serves as a universal API for creator data, simplifying the process for developers. Instead of building separate integrations for platforms like YouTube, TikTok, Patreon, Spotify, and Instagram, Phyllo offers a scalable and reliable solution. By leveraging a single, easy-to-integrate API, developers in the creator economy can efficiently access data from multiple platforms.
Phyllo provides the following YouTube creator data:
- Profile information
- Content feeds
- Audience demographics
- Content views
Phyllo vs. Third-Party Aggregators for YouTube Data
Data Quality: Phyllo delivers highly accurate and reliable creator data directly from the source—platform APIs—ensuring authenticity. In contrast, third-party aggregators often rely on less credible methods like data scraping, which can result in lower data quality.
Partnership with Platforms: Phyllo works in alignment with source platforms, offering superior data pipeline performance. Unlike third-party aggregators that use scraping methods discouraged by platforms, Phyllo ensures compliance and optimal functionality.
Webhooks for Real-Time Updates: Phyllo provides webhooks that notify developers whenever a creator updates their data. This feature improves page load times and eliminates guesswork when requesting data. On the other hand, third-party services rely on asynchronous, on-demand requests, which can lead to delays.
Audience Data Accuracy: Phyllo’s audience data comes directly from platform APIs, providing the same insights that creators see in their dashboards. Third-party aggregators often rely on approximations, which can result in less accurate audience data.
Frequent Data Refreshes: Phyllo refreshes creator data every 24 hours or even sooner, ensuring the most current information. In contrast, third-party aggregators with large databases often refresh data at significantly lower frequencies, reducing its timeliness.
Conclusion
This guide has shed light on the ins and outs of scraping YouTube, covering everything from the basics to advanced techniques. By mastering these methods, you're now equipped to tap into YouTube's vast data reservoir, opening up new possibilities to analyze trends, gather insights, and make data-driven decisions.
As you embark on your YouTube scraping journey, remember to always keep ethics and legality in mind. Respect YouTube's terms of service, implement rate limiting, and use your newfound skills responsibly. With the right approach, YouTube scraping can be a powerful tool in your digital toolkit, helping you stay ahead in the fast-paced world of online content and data analysis.
Looking for a compliant, efficient solution to access YouTube data? Sign up for free and discover how you can retrieve creator-consented data seamlessly.
.avif)
YouTube API: Easy Fixes for Common Problems







.avif)

