.avif)
After a packed September, October proved to be another exciting month at Phyllo with a slew of new product updates. In terms of coverage, the Identity API for LinkedIn is now live and we’ve also launched sandbox support for three new publishing platforms - Substack, Medium and Ghost. There are some nifty upgrades to the Connect SDK too, along with two important additions to our API endpoints. Let’s take a closer look at October’s updates:
Identity for LinkedIn
We’re now live with our Identity product for LinkedIn. It currently allows you to onboard LinkedIn users seamlessly through a consented login process and provides important details including the name and profile picture of the user. These details can enable profile validation use cases on your app and minimize the risk of identity fraud. Identity for LinkedIn is in the beta phase at the moment, and we’ll continuously be enhancing the supported data attributes over the coming weeks. Reach out to our support team at support@getphyllo.com if you have any questions or clarifications on its functionality and available data attributes.
Coverage and Connect SDK Updates
As part of our ever-increasing coverage, we’ve added sandbox support for the following platforms in October:
- Medium - Identity and Engagement APIs
- Ghost - Identity and Engagement APIs
- Gumroad - Identity and Income APIs
With these additions, we now cover the full gamut of publishing platforms on sandbox. This makes it easy for you to build for use cases where verified creators from these publishing apps can check and monitor the performance of their content, follower and subscriber counts etc. Check out our full data guide for a platform-wise list of supported products and data attributes.
In addition to coverage updates, there are some under the hood upgrades to our Connect SDK too. The new performance and design tweaks for Connect will result in improved connection times and better error handling.
Instagram Stories
Instagram Stories is one of the leading formats of content creation for influencers worldwide. However, their engagement metrics (number of likes, shares, views etc) are not publicly available. This means that, for influencer marketing platforms that rely on third party scrapers to fetch influencers’ social data, it is a hassle to get metrics for Stories. Scrapers use a mix of mass approximations and derived data to sometimes report these numbers, but this is not the most reliable solution.
At Phyllo, we report accurate first party data of Instagram Stories and Reels (through Instagram Graph API) to ensure influencing marketing platforms get the metrics they want in a secure and user-consented manner. Today, we actively track more than 1 Million Instagram stories every month and this number continues to grow. Set up a demo with us to check out how Phyllo seamlessly connects with Instagram.
Brand New API endpoints
At Phyllo, we ensure we listen to developer feedback seriously and prioritize those features that will genuinely make an impact in your day-to-day usage of our APIs. Keeping this in mind, we are launching two new API endpoints to refresh the most recent data set for an account and to fetch historical data for certain products. Let’s look at these in more detail:
Refresh Endpoints - The Refresh APIs allow you to force an out-of-turn data refresh of the given products on the given account. This is an asynchronous action, and we notify you through webhooks when the refresh is complete.
One common use case that can be powered with Refresh APIs is when you want to allow the creators on your app to request for the latest data, instead of waiting for the next automatic update. This can even be rolled out as a monetized feature at your end. Another potential use case could be to run a scheduled job (weekly, fortnightly, every 10 days, however you wish) for an account on an on-demand basis.
Historical data Endpoints - By default, we provide data points up to certain periods, for example up to T-90 days for content, up to T-12 months for income, etc., where T is the day on which you call our APIs. But at times, you may want to look at data beyond those ranges. This is where our historic data endpoints can help you. They allow you to tell us a certain date, starting with which you want to collect data for a given product on the given account.
This is an asynchronous action, and we notify you through webhooks when the data collection is complete. Please note that this is a one time action and does not change the default behavior of the APIs. This means if you request for historic data on contents for a certain account for a period of say 6 months, we will get that data for that one time but our regular updates will still follow the T-90 schedule.
Meta’s New, Restrictive Data Policies
Meta's new anti-scraping policies are making it extremely difficult for third-party data aggregators to sustain. This, in turn, is affecting the many industries that rely on this data to make critical business decisions such as influencer marketing. With Phyllo, you do not have to worry about these policies standing in the way of realizing your business use cases. It gives you continuous access to verified, user-consented data across hundreds of platforms.
Phyllo differs from scrapers in the following aspects:
- It provides the right data infrastructure for first party creator data as opposed to only publicly available information that is obtained through third party scrapers
- It works directly with the source platform APIs to report accurate data and does not run mass approximations
- It provides data across different content formats such as Instagram stories and YouTube Shorts
- It offers better performance, faster data refresh frequencies, comprehensive documentation and a robust webhook system in comparison to scrapers. Learn more about the differences between Phyllo and data scrapers here.
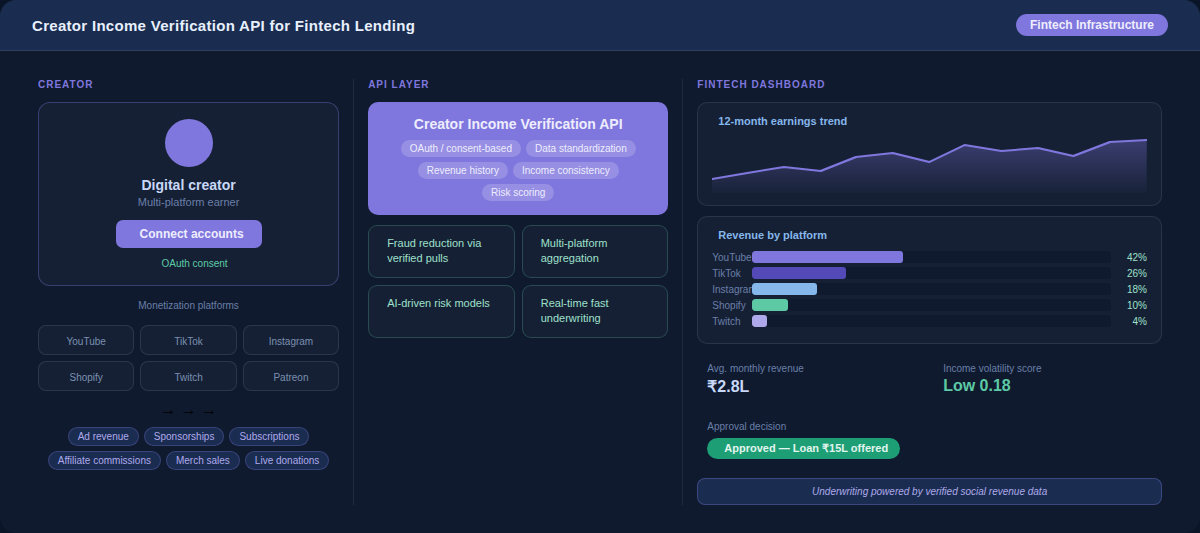
Income API Updates
Phyllo’s Income APIs are continuing to open a world of opportunities for companies in the fintech space to build exciting products with the verified income data of creators. With support for both social and commerce platforms, they let you:
- Get daily updates from all income streams, making it easier for financial institutions to verify the numbers
- Segregate income by transaction and date. Example: Monday - $10 - subscription revenue
- Streamline the underwriting process with access to first-party data
- Reduce manual processes like verifying screenshots
- Analyze historical income trends for better decision-making
Income APIs are now live for YouTube and AdSense and support 9 platforms in sandbox. We’d love for you to try them out and share your feedback.
That sums up an exciting October at Phyllo. We hope you have a fantastic experience trying these new updates across the board. We look forward to an equally exciting November!