Enterprises today rely heavily on social and web data to drive decisions around marketing, risk management, customer experience, and product strategy. The challenge is not just getting access to this data, but doing so in a way that is stable, compliant, and secure.
Two popular approaches exist for collecting large amounts of online data: web scraping and social data APIs. At first glance, both seem capable of delivering the information enterprises need. However, the way they work and the risks they introduce are very different.
This guide breaks down both methods in detail, compares them across key enterprise criteria, and helps you understand which option is safer and more future proof for serious business use.
Understanding the Basics of Web Scraping
To evaluate safety, we first need to understand what web scraping actually involves and why companies use it.
Web scraping is the automated extraction of information directly from website pages. A script or bot visits a URL, reads the HTML that a normal browser would load, and then pulls out specific pieces of information such as text, images, or links.
Why teams turn to scraping
Before any deep dive into risks, it is useful to see why scraping is attractive in the first place.
Common motivations include:
- Quick access to publicly visible data
- No need to wait for official integrations
- Freedom to extract almost any visible field on a page
- Low initial setup cost for small projects
Typical use cases are:
- Competitor price monitoring
- Tracking reviews or mentions
- Collecting contact or profile data
- Building datasets for research or experiments
For a proof of concept, scraping can feel fast and flexible. The problems appear when you try to run it at enterprise scale.
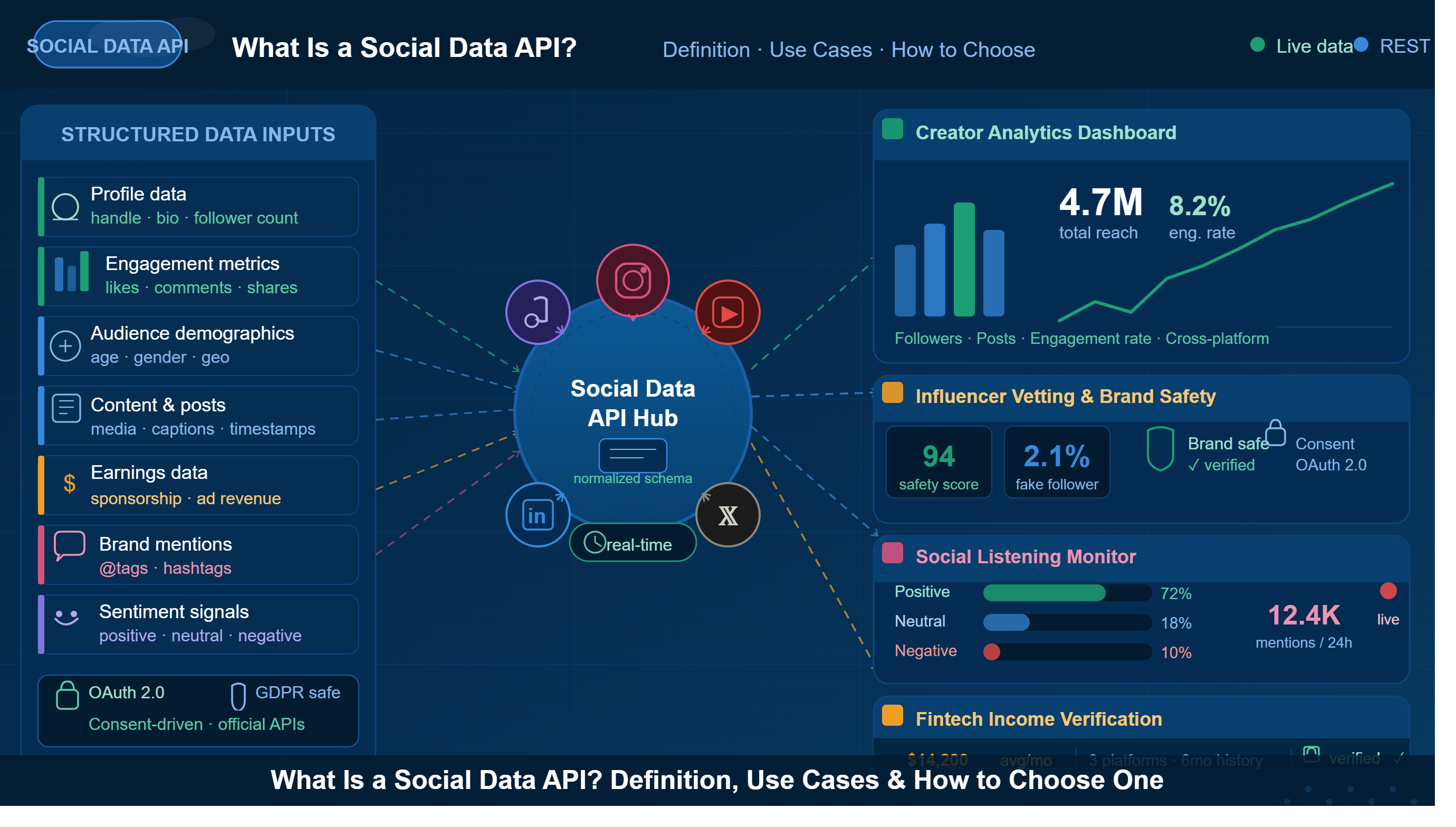
What Are Social Data APIs?
Instead of reading raw web pages, APIs provide a structured, official way to request data.
An API is an interface exposed by a platform or a trusted data provider. You send a request to a defined endpoint and receive clean, structured data such as JSON in return. No HTML parsing is required.
Why APIs exist and how they help
Before comparing safety, it helps to see what APIs are designed for.
APIs are built to:
- Deliver consistent, machine readable data
- Enforce access controls and permissions
- Support high volume, repeatable requests
- Maintain compatibility as platforms evolve
For enterprises that need reliable pipelines, APIs remove the guesswork of scraping page layouts. A good example is a unified social data service such as the Social Data API available at Phyllo.
This kind of API abstracts away platform complexity and provides compliant access to social data through stable endpoints.
Legal and Compliance Risks of Web Scraping
When discussing safety for enterprises, legal exposure is one of the first concerns.
Many websites explicitly forbid automated scraping in their terms of service. Even if data is publicly visible, automated extraction can still be considered a violation of those terms.
Key legal challenges
Before you build anything large, you must consider these risks:
- Breach of platform terms of service, leading to bans or legal notices
- Potential copyright issues when storing or redistributing scraped content
- Accidental collection of personal or sensitive data
- Conflicts with privacy laws such as GDPR or similar regulations
Large enterprises are attractive legal targets. What might be ignored for a hobby project can trigger enforcement when done at scale by a company.
Technical Fragility of Scraping
Beyond legality, scraping is inherently brittle.
Web pages are built for humans, not for data pipelines. A small visual redesign can break your parser overnight.
Ongoing maintenance burden
Before relying on scraping in production, consider the constant upkeep required:
- HTML structure changes require code updates
- Dynamic JavaScript content needs complex rendering tools
- Anti bot systems introduce captchas and blocks
- IP bans force you to manage rotating proxy networks
This turns into a continuous engineering task rather than a one time build. Over time, maintenance costs often exceed initial development effort.
Security Risks Introduced by Scrapers
Enterprises must also think about internal security, not just external blocking.
A large scraping system often needs distributed workers, proxy providers, and third party libraries. Each piece increases your attack surface.
Common security concerns
Before deploying scraping infrastructure, be aware of:
- Untrusted proxy networks that can log or tamper with traffic
- Execution of unknown scripts while rendering pages
- Dependency on third party scraping frameworks
- Higher risk of ingesting malicious or poisoned content
For regulated industries, these risks alone can make scraping unacceptable.
Compliance and Governance Advantages of APIs
APIs are designed with permissions and compliance in mind from the start.
Instead of bypassing site interfaces, you are using an approved data access channel with clear rules.
How APIs reduce legal exposure
Before worrying about lawsuits or bans, APIs provide built in safeguards:
- Explicit contracts and usage terms
- Controlled data scopes and fields
- Authentication and authorization checks
- Easier auditing of who accessed what data and when
This structure aligns much better with enterprise governance and audit requirements.
Reliable and Structured Data Delivery
APIs return predictable, well defined data structures.
You do not need to guess which div contains the number you want. You receive named fields with consistent types.
Practical benefits for data teams
Before building analytics on top, APIs give you:
- Stable schemas across time
- Clear versioning when changes occur
- Rich metadata such as timestamps and IDs
- Built in filtering and pagination
This dramatically reduces data cleaning and parsing effort compared to scraping raw HTML.
Scalability Without Infrastructure Headaches
Scraping at scale means running many parallel crawlers and handling blocks and retries yourself.
APIs shift most of that burden to the provider.
What enterprises gain from API based scaling
Before investing in your own crawling farm, APIs offer:
- Managed rate limits instead of sudden bans
- High availability endpoints
- Backoff and quota signals instead of hard failures
- Easier horizontal scaling of your own consumers
You focus on using data, not fighting websites.
Direct Comparison: Scraping vs APIs
To make the tradeoffs concrete, here is a side by side view.
For enterprises, most rows in this table favor APIs.
When Scraping Might Still Be Used
There are limited scenarios where scraping can make sense.
Before defaulting to APIs, consider scraping only if:
- No official or third party API exists
- Data is needed for short term research
- Explicit permission from the site owner is granted
- Volume is low and legal review is complete
Even then, it is usually safer to treat scraping as temporary, not foundational infrastructure.
Where Social Data APIs Shine
For long term, production grade systems, APIs are usually the right choice.
Before launching enterprise features, APIs are ideal for:
- Brand and reputation monitoring
- Fraud and risk detection
- Market and trend analytics
- Creator or influencer insights
- Large scale dashboards and reporting
Using a dedicated social data API lets teams build products instead of maintaining scrapers.
Ethical and Privacy Considerations
Safety is not only about avoiding lawsuits. It is also about respecting user privacy.
APIs typically enforce clearer boundaries on what data can be accessed and how it can be used.
Responsible data practices to follow
Before storing or sharing any collected data:
- Collect only what you truly need
- Avoid sensitive personal attributes unless strictly required
- Define retention and deletion policies
- Ensure transparency in how data is used
API based access makes it easier to align with these principles because permissions and scopes are explicit.
Total Cost of Ownership
Scraping looks cheap at the start but expensive over time.
Hidden costs include constant fixes, proxy services, legal review, and incident response when blocks or breaches occur.
Why APIs often win on cost
Before choosing based on upfront price alone, consider that APIs provide:
- Predictable pricing models
- Minimal maintenance engineering
- Lower legal and compliance risk
- Faster time to market for new features
For enterprises, this often results in lower total cost even if per request fees exist.
Final Verdict: The Safer Enterprise Choice
When judged on legality, reliability, security, and scalability, social data APIs are clearly safer for enterprises.
Web scraping can be useful for experiments or niche cases, but it introduces ongoing legal uncertainty and technical fragility. At enterprise scale, those risks compound quickly.
APIs provide structured, permissioned, and auditable access to the data you need. By using a compliant and unified solution such as a social data API platform, organizations can focus on insights and innovation rather than fighting website defenses.
For most serious business applications, APIs are the safer and more sustainable foundation.
FAQs
1. Is web scraping always illegal for companies?
Not always, but it frequently violates website terms of service and can create legal risk. Even if not strictly illegal, large scale scraping can lead to bans, cease and desist letters, or litigation, which makes it risky for enterprises.
2. Do APIs limit what data I can access?
APIs may restrict certain fields, but they provide reliable and compliant access to the most important data. In practice, the stability and legality usually outweigh the loss of a few edge case fields.
3. Is scraping cheaper than using an API?
It can be cheaper at the very beginning, but long term costs for maintenance, proxies, legal review, and outages often make scraping more expensive overall for enterprises.
4. Can we wrap our own scraper behind an internal API?
You can, but this does not remove the underlying legal and technical risks. It only hides them behind another layer, while the fragility and compliance issues remain.
5. How do APIs help with privacy compliance?
APIs enforce clear access scopes and authentication, making it easier to respect user consent and regulatory limits. This structure supports auditing and controlled data use.
6. What should enterprises evaluate before choosing a method?
They should assess legal compliance, long term maintenance effort, security exposure, scalability needs, audit requirements, and total cost of ownership. In most cases, that evaluation points toward social data APIs as the safer option.